情報理論において、シャノンの情報源符号化定理(シャノンのじょうほうげんふごうかていり、英語: Shannon's source coding theorem, noiseless coding theorem)は、データ圧縮の可能な限界と情報量(シャノンエントロピー)の操作上の意味を確立する定理である。1948年のクロード・シャノンの論文『通信の数学的理論』で発表された。シャノンの第二基本定理(通信路符号化定理)に対してシャノンの第一基本定理とも言う。
情報源符号化定理によれば、(独立同分布(iid)の確率変数のデータの列の長さが無限大に近づくにつれて)、符号化率(記号1つ当たりの平均符号長)が情報源のシャノンエントロピーよりも小さいデータを、情報が失われることが事実上確実ではないように圧縮することは不可能である。しかし、損失の可能性が無視できる場合、符号化率を任意にシャノンエントロピーに近づけることは可能である。
シンボルコードの情報源符号化定理は、入力語(確率変数と見なされる)のエントロピーとターゲットアルファベットの大きさの関数として、符号語の可能な期待される長さに上限と下限を設定する。
提示
情報源符号化とは、情報源の記号(の列)からアルファベット記号(通常はビット)の列への写像である。情報源の記号は二進数ビットから正確に復元できる(可逆圧縮)か、何らかの歪みを伴って復元される(非可逆圧縮)。これが、データ圧縮の背後にあるコンセプトである。
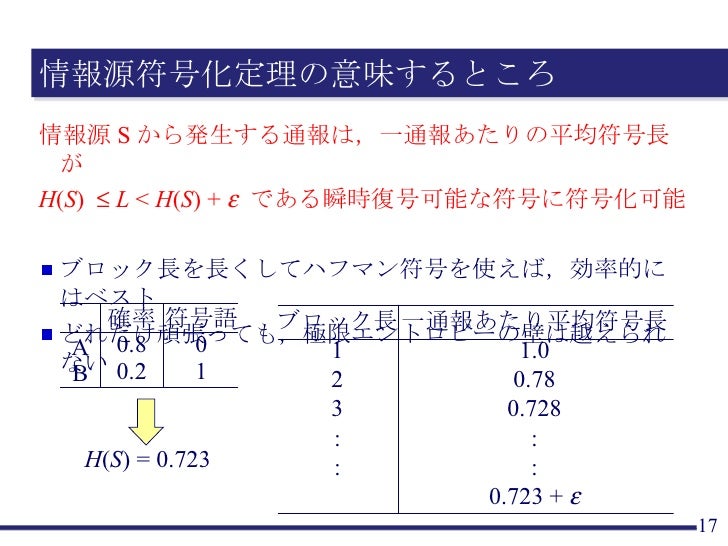
情報源符号化定理
情報源符号化定理(Shannon 1948)は以下のように非形式的に提示されている(MacKay 2003, pg. 81, Cover:Chapter 5)。
情報量 H(X) を持つ N 個の独立同分布の確率変数は、N → ∞のとき、無視できるほどの情報損失のリスクをもって N H(X) ビット以上に圧縮できる。しかし、N H(X) ビット以下に圧縮されたとき、情報が失われることは事実上確実である。
シンボルコードの情報源符号化定理
Σ1, Σ2 を2つの有限のアルファベットとし、Σ∗
1 と Σ∗
2 をそれぞれのアルファベットからの全ての有限語の集合とする。
X を Σ1 の値をとる確率変数とし、 f を Σ∗
1 から Σ∗
2 への一意復号可能な符号とする(ここで、|Σ2| = a)。S を単語長 f (X) で与えられる確率変数とする。
f が X の最小単語長さという意味で最適であるとき、
である。(Shannon 1948)
証明
情報源符号化定理の証明
X が独立同分布(iid)な情報源であるとき、その時系列 X1, ..., Xn は、離散値の場合はエントロピー H(X) 、連続値の場合は差分エントロピーで独立同分布となる。情報源符号化定理によれば、情報源のエントロピーより大きい任意のレートの任意の ε > 0 に対して、十分に大きい n と、情報源 X1:n の独立同分布な n 個の複写をとり、これを n(H(X) ε) この二進数ビットに写像するエンコーダがあり、それは、少なくとも 1 − ε の確率で、情報源記号 X1:n が二進数ビットから復元できる。
達成可能性の証明。 いくつかの ε > 0 を修正し、
とする。典型集合 Aε
n は、以下のように定義される。
漸近的等分配性(AEP)が示すところによると、十分に大きい n に対して、情報源によって生成された列が典型集合 Aε
n に含まれる確率は 1 に近づく。特に、十分に大きい n に対しては、 は任意に 1 に近く、具体的には より大きくすることができる。
典型集合の定義は、典型集合にある列が以下を満足することを意味する。
注意:
- Aε
nから導かれる列 の確率は 1 − ε より大きい。
- の左側(下限)からは となる。
- の右側(上限)および全体集合 Aε
n の全確率に対する下限からは となる。
よって、 ビットはこの集合の任意の文字列を指すのに十分である。
エンコードアルゴリズム : エンコーダは、入力列が典型集合内にあるかどうかをチェックする。そうであれば、典型集合内の入力列のインデックスを出力する。そうでなければ、エンコーダは任意の n(H(X) ε) 桁の数を出力する。入力列が典型集合内にある限り(少なくとも 1 − ε の確率で)、エンコーダは何の誤りも生じない。従って、エンコーダの誤りの確率の上限は ε である。
逆の証明。その逆は、Aε
n より小さいサイズの集合が 1 から離れる確率の集合をカバーすることを示すことで証明できる。
シンボルコードの情報源符号化定理の証明
1 ≤ i ≤ n について、si をそれぞれ可能な xi の語長とする。 と定義する。ここで、 C は q1 ... qn = 1 となるように選択される。
ここで、2行目はギブスの不等式に、5行目はクラフトの不等式による。
よって log C ≤ 0 である。
2行目の不等式について、
とすると、
であり
であり
よって、クラフトの不等式には、これらの語長を持つ接頭辞のない符号が存在する。従って、最小の S は以下を満たす。
非定常独立系への拡張
離散時間非定常独立情報源のための固定レート可逆情報源符号化
典型集合 Aε
n を
と定義する。
次に、与えられた δ > 0 に対して、 n が十分に大きい場合、 Pr(Aε
n) > 1 − δ である。あとは、典型集合の列をエンコードするだけであり。情報源符号化の通常の方法は、この集合の濃度が であることを示す。
従って、1 − δ より大きい確率で符号化するには、平均して Hn(X) ε ビットで十分である。ここで、n を大きくすることによって、ε と δ を任意に小さくすることができる。
関連項目
- 通信路符号化
- シャノンの通信路符号化定理
- 誤り指数
- 漸近的等分配性 (AEP)
脚注